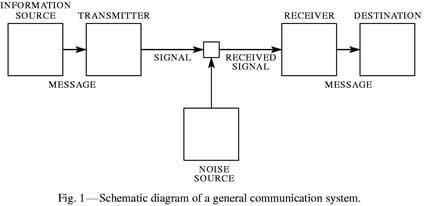
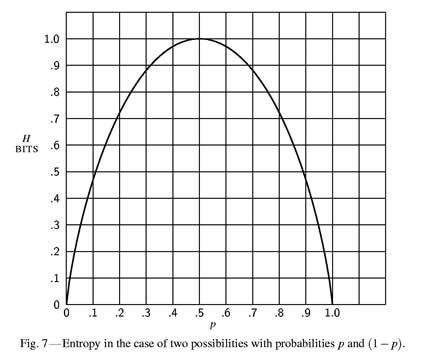
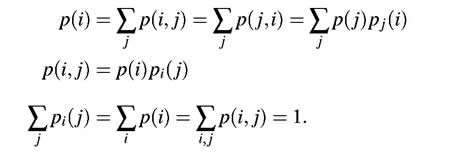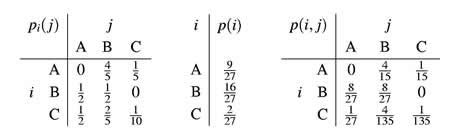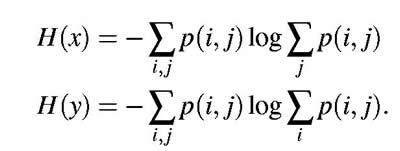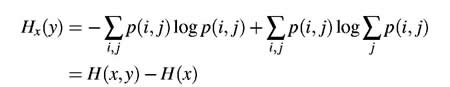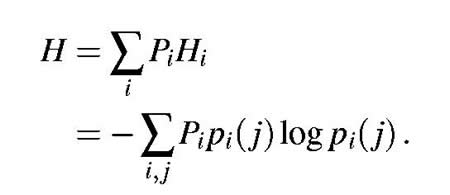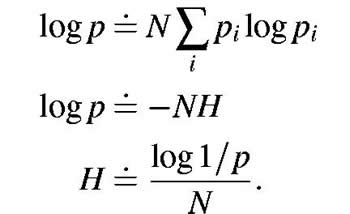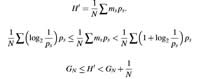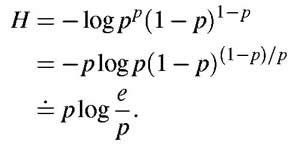| We now consider
the information source. How is an information source to be described mathematically,
and how much information in bits per second is produced in a given source?
The main point at issue is the effect of statistical knowledge about the
source in reducing the required capacity of the channel, by the use of
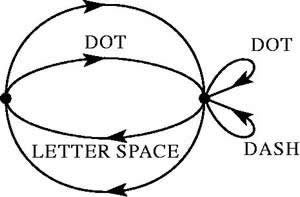
proper encoding of the information. In telegraphy, for example, the messages
to be transmitted consist of sequences of letters. These sequences, however,
are not completely random. In general, they form sentences and have the
statistical structure of, say, English. The letter E occurs more frequently
than Q, the sequence TH more frequently than XP, etc. The existence of
this structure allows one to make a saving in time (or channel capacity)
by properly encoding the message sequences into signal sequences. This
is already done to a limited extent in telegraphy by using the shortest
channel symbol, a dot, for the most common English letter E; while the
infrequent letters, Q, X, Z are represented by longer sequences of dots
and dashes. This idea is carried still further in certain commercial codes
where common words and phrases are represented by four- or five-letter
code groups with a considerable saving in average time. The standardized
greeting and anniversary telegrams now in use extend this to the point
of encoding a sentence or two into a relatively short sequence of numbers.
|
| We can think of
a discrete source as generating the message, symbol by symbol. It will
choose succes sive symbols according to certain probabilities depending,
in general, on preceding choices as well as the particular symbols in
question. A physical system, or a mathematical model of a system which
produces such a sequence of symbols governed by a set of probabilities,
is known as a stochastic process. 3 We may consider a discrete
source, therefore, to be represented by a stochastic process. Conversely,
any stochastic process which produces a discrete sequence of symbols chosen
from a finite set may be considered a discrete source. This will include
such cases as: |
| |
| 1. Natural written
languages such as English, German, Chinese. |
| |
| 2. Continuous information
sources that have been rendered discrete by some quantizing process. For
example, the quantized speech from a PCM transmitter, or a quantized television
signal. |
| |
| 3. Mathematical
cases where we merely define abstractly a stochastic process which generates
a se quence of symbols. The following are examples of this last type of
source. |
| |
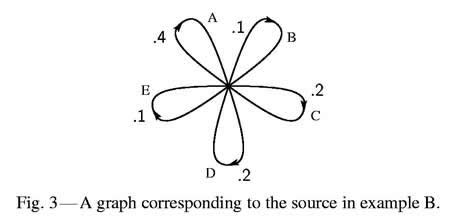
| (A) Suppose we
have five letters A, B, C, D, E which are chosen each with probability
.2, successive choices being independent. This would lead to a sequence
of which the following is a typical example. |
| |
| BDCBCECCCADCBDDAAECEEA
ABBDAEECACEEBAEECBCEAD. |
| |
|
This was constructed with the use of a table of random numbers.
(B) Using the same five letters let the probabilities be .4, .1, .2,
.2, .1, respectively, with successive choices independent. A typical
message from this source is then:
AAACDCBDCEAADADACEDA EADCABEDADDCECAAAAAD.
|
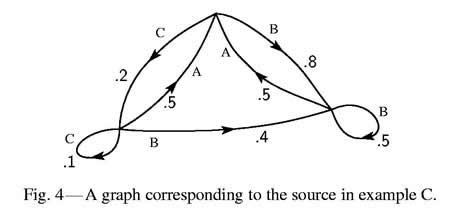
| (C) A more complicated
structure is obtained if successive symbols are not chosen independently
but their probabilities depend on preceding letters. In the simplest case
of this type a choice depends only on the preceding letter and not on
ones before that. The statistical structure can then be described by a
set of transition probabilities pi (j), the probability that letter i
is followed by letter j. The indices i and j range over
all the possible symbols. A second equivalent way of specifying the structure
is to give the "digram" probabilities p(i, j), i.e., the relative frequency
of the digram i j. The letter frequencies p(i), (the probability
of letter i), the transition probabilities |
| |
| 3
See, for example, S. Chandrasekhar, "Stochastic Problems in Physics and
Astronomy," Reviews of Modern Physics, v. 15, No. 1, January 1943,
p. 1. |
| 4 Kendall
and Smith, Tables of Random Sampling Numbers, Cambridge, 1939.
5 |