Introduction to Supercomputers
this
page will be continually updated.
We all probably heard of supercomputers. But when you think of a supercomputer do you think of HAL2000, and other Science Fiction stuff? Right!
Unlike mainframes and minicomputers. Super computers are used for the heavy stuff like weather maps, construction of atom bombs, finding oil, earthquake prediction, and sciences where a lot of calculations have to be done. They also are used to help governments eavesdrop on anything there is passing through telephone, datalines, e-mail, radiowaves, anything that is written etc. etc.
As you can see in the table the ranking of a supercomputer is at the top of the computer spectrum.
| Quantum computers | |
| Grid computers | |
| Supercomputers | |
| Mainframes | |
| Mini computers | |
| Microcomputers | |
| Terminals | |
| Embedded computers |
Note: Quantum computers only exists on paper, apart from some experimental setups. Grid computers are comparable with supercomputers but are a lot cheaper.
Historically, a supercomputer is associated with the fastest computer available. Sometimes also the largest in size. Supercomputing stands for: "mass computing at ultra highspeed".
Definition
Many definitions(2) of supercomputers have come and gone. Some favorites of the past are
In general a supercomputer performs “above normal computing,” in the sense that a superstar is “above” the other stars. And, yes you can build your own personal super computer. In a later chapter on "Grid" computing this will be explained. Note, that “super-anything” does not mean the absolute fastest or best.
Though all contemporary personal computers perform in the tens or hundreds of megaflops (millions of calculations per second), they still can not solve certain problems fast enough. It is only in the beginning of 2000 that the supercomputing arena moves into the gigaflops region. What this means is that you can have a computer calculate problems at the speed of a few gigaflops, but doing the same calculations at "just" 100 megaflops and within acceptable time too is almost impossible. Meaning, with supercomputers you can do calculations within a time limit or session that is acceptable to the user. Namely: YOU.
To put it stronger: you can do anything in real time (meaning: now, right away, immediately) with a supercomputer that cannot be done in your lifetime with one single PC.

screen dump of NEC's ESS
So, certain tasks are, in some ways, not possible to do in real time on PCs.(2) For example it will take a single PC more than a few days (weeks) to calculate a weather map. Resulting in the predictions of the weather several days old when the map is finished. That doesn't sound much like a prediction, does it? A supercomputer does the same job in a few minutes. That's more like what we as users want: top speed.
The issue of costs and time
Construction of supercomputers is an awesome and very expensive task. To get a machine from the laboratory to the market may take several years. The most recent development costs of supercomputers may vary between 150 to 500 million dollars or more. You can imagine that a project like that draws on all the resources a company has. One of the major reasons that the development of a supercomputer is kept very hush hush. The latest supers are only possible to create with help of governments and one or more large size companies.
Using a supercomputer is expensive as well. And as a user you are charged according
to the time you use the system what is expressed in the number of processor
(CPU) seconds your program runs. In the recent past Cray
(one of the first supercomputers) time was $1,000 per hour. The use of this
"Cray time" was a very common way to express computer costs in time
and dollars.
The need
Why do we need a supercomputer? Well as a normal person from the street you don't. Though your cell phone or PDA has more computing power than the first mainframes like the ENIAC or Mark1. So with the information glut flooding your senses, and the bloating software trying to channel that, we will probably need extreme computing power in maybe a few decades. The architecture in creating that power is already on the horizon: wireless LANs, info bot technology, grid computing and virtual computing centers thus shared computing etc etc. will be part of our daily used equipment. Even computers will be sewn into our clothing. (See MIT's wearable computing project)
Who really needs supercomputing today are mostly scientists. Doing whatever
they do in mass computing at ultra high speed. They use such computers in all
thinkable disciplines: space exploration and related imagery (picturing galaxies
and intergalactic matter), environmental simulations (global warming effects)
mathematics, physics (the search for the really smallest part of matter), gene
technology (what gen is it that makes us old) and there are many other examples.
More real world examples are: industrial and technological applications, world
spanning financial and economical systems in which speed is essential. Also
more and more superscomputers are used for creating simulations for building
airplanes, creating new chemical substances, new materials, testing car crashes
without having to crash a car. And many more applications where it will take
more than a few days to get the results or are impossible to calculate.
Chronology
Below follows a short narrative on how supercomputers evolved from mainframes and alike. Again the need to develop supers did not come out of the blue. Government and private companies alike acted on the need of the market. The need to bring down the costly computer time and to calculate as fast as possible to save time thus money. The latter is not allways the primary reason.
Up to 1965 there were some experimental super computers. But the first succesfull one was the CDC 6600.
| 1939 | Atanasoff-Berry Computer created at Iowa State |
| 1940 | Konrad Zuse -Z2 uses telephone relays instead of mechanical logical circuits |
| 1943 | Colossus - British vacuum tube computer |
 |
 |
| ENIAC 1942 | Manchester mark1 1944 |
| 1946 | J. Presper Eckert & John Mauchly, ACM, AEEI, ENIAC, |
 Harvard
mark II Harvard
mark II |
|
| 1947 | First Transistor, Harvard Mark II (Magnetic Drum Storage) |
 whirlwind whirlwind |
|
| 1948 | Manchester Mark I (1st stored-program digital computer), Whirlwind at MIT |
 Univac
I Univac
I |
|
| 1950 | Alan Turing-Test of Machine Intelligence, Univac I (US Census Bureau) |
| 1951 | William Shockley invents the Junction Transistor |
| 1952 | Illiac I, Univac I at Livermore predicts 1952 election, MANIAC built at Los Alamos, AVIDAC built at Argonne |
  edvac edvacIBM 701 1953 |
| 1953 | Edvac, IBM 701 |
 |
|
| 1954 | IBM 650 (first mass-produced computer), FORTRAN developed by John Backus |
| 1955 | Texas Instruments introduces the silicon transistor, Univac II introduced |
 |
 |
|
| IBM 704 1956 | IAS |
| 1956 | MANIAC 2, DEUCE (fixed head drum memory), clone of IAS |
| 1958 | Nippon Telegraph & Telephone Musasino-1: 1st parametron computer, Jack Kilby-First integrated circuit prototype; Robert Noyce works separately on IC's, NEC 1101 & 1102 |
 |
|
| 1960 | Paul Baran at Rand develops packet-switching, NEAC 2201, Whirlwind-air traffic control, Livermore Advanced Research Computer (LARC), Control Data Corporation CDC 1604, First major international computer conference |
 Stretch Stretch |
|
| 1961 | IBM Stretch-Multiprogramming |
|
|
|
| 1962 | Control Data Corporation opens lab in Chippewa Falls headed by Seymour Cray, Telestar launched, Atlas-virtual memory and pipelined operations, Timesharing-IBM 709 and 7090 |
 IBM
360 IBM
360 |
|
| 1964 | IBM 360-third generation computer family. Limited test ban treaty IEEE formed |
| 1965 | The Sage System, |
Before this year of 1965 there were mighty computers akin to what are called Mainframes. Fast but not fast enough. And as usual developments set in motion in the "pre-super" era laid the basis for what follows. Also the industry and government organizations primarely in the USA felt the urgent need for faster computing. Since calculating a simple stress module for designing engines took several days on a contemporary mainframe, sucking up all available resources. The need for a new class of computing was almost palpable: Supercomputing And it was Seymour Cray that brought it to us.
| 1965 |
CDC 6600 designed by Seymour Cray (First commercially successful supercomputer-speed of 9 megaflops) |
| 1966 | RS-232-C standard for data exchange between computers & peripherals, IBM 1360 Photostore-onlne terabit mass storage |
| 1967 | CMOS integrated circuits, Texas Instruments Advanced Scientific Computer (ASC) |
| 1968 | RAND-decentralized communication network concept, Donald Knuth-algorithms & data structures separate from their programs, Univac 9400 |
| 1969 | Arpanet, Seymour Cray-CDC 7600 (40 megaflops) |
| 1970 | Unix developed by Dennis Ritchie & Kenneth Thomson |
 Cray 1 - 1976 (courtesy Cray Inc.) |
|
| 1976 | Cray Research-CRAY I vector architecture (designed by Seymour Cray, shaped the computer industry for years to come), Datapoint introduces ARC (first local area network) |
| 1978 | DEC introduces VAX11/780 (32 bit super/minicomputer) |
| 1979 | Xerox, DEC, Intel - ethernet support |
| 1980 | David A. Patterson and John Hennessy "reduced instruction set", CDC Cyber 205 |
 Cray
xmp (courtesy Cray Inc.) Cray
xmp (courtesy Cray Inc.) |
|
| 1982 | Cray X-MP, Japan-fifth generation computer project is intended for research into Artificial intelligence. The project goals will never be reached but the spin off of this project is very rewarding towards other supercomputing projects. |
| 1984 | Thinking Machines and Ncube are founded- parallel processing, Hitachi S-810/20, Fujitsu FACOM VP 200, Convex C-1, NEC SX-2 |
 tmc
9 tmc
9 |
|
| 1985 | Thinking Machines Connection Machine, |
| 1986 | IBM 3090 VPF. |
| 1987 |
Evans and Sutherland ES-1, Fujitsu VP-400E, NSFnet established |
| 1988 | Apollo, Ardent, and Stellar Graphics Supercomputers, Hitachi S-820/80, Hypercube simulation on a LAN at ORNL, |
| 1989 |
CRAY Y-MP, Tim Berners-Lee: World Wide Web project at CERN, Seymour Cray: Founds Cray Computer Corp.-Begins CRAY 3 using gallium arsenide chips, |
| 1990 | Bell Labs: all-optical processor, Intel launches parallel supercomputer with RISC microprocessors; |
|
|
|
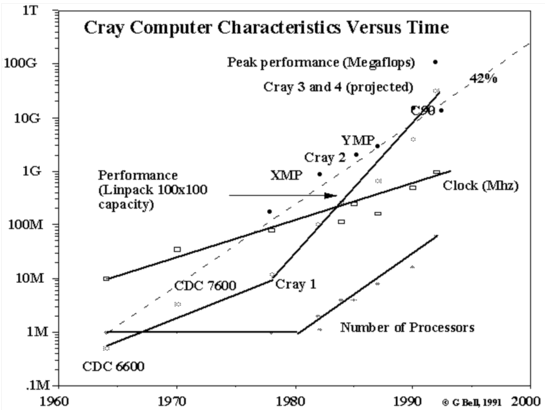
| 1991 |
Gordon Bell projects the speed of the next few Cray supercomputers Japan announces plans for sixth-generation computer based on neural networks; First M-bone audio multicast transmitted on the Net; NEC SX-3, Hewlett-Packard and IBM-RISC based computers; Fujitsu VP-2600; |
| 1992 | Thinking Machines CM-5 |
 Cray
T3D (courtesy Cray Inc.) Cray
T3D (courtesy Cray Inc.) |
|
| 1993 | CRAY T3D |
| 1994 | Netscape, NCSA Mosaic; Leonard Adleman-DNA as computing medium; |
 intel
ASCI red intel
ASCI red |
|
| 1997 | ASCI Red -- first teraflop computer delivered
|
| 2000 |
Blue Gene is IBM's first special purpose supercomputer and will be used for modeling human proteins. Unraveling of the human genetic code can help pharmaceutical laboratories to develop medicines. |
| 2002 |
Nec's Earth Simulator running at 35.61 TFlops (trillion operations per second) The Earth Simulator consists of 640 supercomputers. Primarily designed for environmental simulations. |
| 2004 | In a few years architectures of supers changed dramatically
|
There are in principle several ways you can design a super computer and there is only one judge: speed, speed and speed.
The following excerpt is from a 1989 lecture of Gordon Bell and illustrates nicely the contemporary design pitfalls.
The Eleven Rules of Supercomputer Design (7)
1) Performance, performance, performance. People are buying supercomputers for performance. Performance, within a broad price range, is everything. Thus, performance goals for Titan were increased during the initial design phase even though it increased the target selling price. Furthermore, the focus on the second generation Titan was on increasing performance above all else. 2) Everything matters. The use of the harmonic mean for reporting performance on the Livermore Loops severely penalizes machines that run poorly on even one loop. It also brings little benefit for those loops that run significantly faster than other loops. Since the Livermore Loops was designed to simulate the real computational load mix at Livermore Labs, there can be no holes in performance when striving to achieve high performance on this realistic mix of computational loads. 3) Scalars matter the most. A well-designed vector unit will probably be fast enough to make scalars the limiting factor. Even if scalar operations can be issued efficiently, high latency through a pipelined floating point unit such as the VPU can be deadly in some applications. The P3 Titan improved scalar performance by using the MIPS R3010 scalar floating point coprocessing chip. This significantly reduced overhead and latency for scalar operations. 4) Provide as much vector performance as price allows. Peak vector performance is primarily determined by bus bandwidth in some circumstances, and the use of vector registers in others. Thus the bus was designed to be as fast as practical using a cost-effective mix of TTL and ECL logic, and the VRF was designed to be as large and flexible as possible within cost limitations. Gordon Bell's rule of thumb is that each vector unit must be able to produce at least two results per clock tick to have acceptably high performance. 5) Avoid holes in the performance space. This is an amplification of rule 2. Certain specific operations may not occur often in an "average" application. But in those applications where they occur, lack of high speed support can significantly degrade performance. An example of this in Titan is the slow divide unit on the first version. A pipelined divide unit was added to the P3 version of Titan because one particular benchmark code (Flo82) made extensive use of division. 6) Place peaks in performance. Marketing sells machines as much or more so than technical excellence. Benchmark and specification wars are inevitable. Therefore the most important inner loops or benchmarks for the targeted market should be identified, and inexpensive methods should be used to increase performance. It is vital that the system can be called the "World's Fastest", even though only on a single program. A typical way that this is done is to build special optimizations into the compiler to recognize specific benchmark programs. Titan is able to do well on programs that can make repeated use of a long vector stored in one of its vector register files. 7) Provide a decade of addressing. Computers never have enough address space. History is full of examples of computers that have run out of memory addressing space for important applications while still relatively early in their life (e.g., the PDP-8, the IBM System 360, and the IBM PC). Ideally, a system should be designed to last for 10 years without running out of memory address space for the maximum amount of memory that can be installed. Since dynamic RAM chips tend to quadruple in size every three years, this means that the address space should contain 7 bits more than required to address installed memory on the initial system. A first-generation Titan with fully loaded memory cards uses 27 bits of address space, while only 29 bits of address lines are available on the system bus. When 16M bit DRAM chips become available, Titan will be limited by its bus design, and not by real estate on its memory boards. 8) Make it easy to use. The "dusty deck" syndrome, in which users want to reuse FORTRAN code written two or three decades early, is rampant in the supercomputer world. Supercomputers with parallel processors and vector units are expected to run this code efficiently without any work on the part of the programmer. While this may not be entirely realistic, it points out the issue of making a complex system easy to use. Technology changes too quickly for customers to have time to become an expert on each and every machine version. 9) Build on other's work. One mistake on the first version of Titan was to "reinvent the wheel" in the case of the IPU compiler. Stardent should have relied more heavily on the existing MIPS compiler technology, and used its resources in areas where it could add value to existing MIPS work (such as in the area of multiprocessing). 10) Design for the next one, and then do it again. In a small startup company, resources are always scarce, and survival depends on shipping the next product on schedule. It is often difficult to look beyond the current design, yet this is vital for long term success. Extra care must be taken in the design process to plan ahead for future upgrades. The best way to do this is to start designing the next generation before the current generation is complete, using a pipelined hardware design process. Also, be resigned to throwing away the first design as quickly as possible. 11) Have slack resources. Expect the unexpected. No matter how good the schedule, unscheduled events will occur. It is vital to have spare resources available to deal with them, even in a startup company with little extra manpower or capital. |
Supercomputers took two major evolutionary paths: vector and scalar processing. As you can see from the graph below there is a big difference.

Vector calculations go 7 times faster by the click graph G. Bell 1989
The way scalar of vector calculations are executed is principally different. On thing is sure vector based processors are more expensive. Not because of economics but for technical / architecturial reasons, vector cpu's are simply much more complex. The ESS from NEC in 2002 is a super based on vector processors, and also the fastest for the next few years.
Also the architecture is sometimes based on embedded technology in the central processors and sometimes it is entirely left over to the operating system c.s software. And of course something in between. But almost allways specialty processors and a lot of peripheral support is build specificaly for the (mostly) unique machine.
But since the late 1990's a new architecture comes into general interest: Grid computing. This allows architects to design a super around off the shelf computer parts like the one in September 2003 built by Verginia Tech from 1100 boxes Apple G5 2200 Mac G5 processors costing "only" 5.2 million USD reaching 10+ Terraflops reaching the top 3 of the top 500 ranking list.
to see a promotional of this super: http://images.apple.com/movies/us/apple/g5_va_tech_mwsf_2004/va_tech_480.mov
The construction of supercomputers is something you have to plan very careful
because once underway there is no going back to do some major revision. If that
happens the company looses millions of dollars and that can result in either
canceling the project and try to make some money from the technology developed
or a company goes broke or almost broke, in any case financially weakened and
will be absorbed by another company. An example is Cray,
since 2000 an independant company again, but they had a few difficult years.
Mismanagement is another factor that causes supercomputer projects to go bust:
an example is the fifth generation project in Japan.
A lot of spin off came from that, very true. But imagine the possibilities if
the Japanese had succeeded.
Third is of cause periods of economic malaise. Projects get stalled. A fine
example of that is Intel. That company scrapped in 2002 its supercomputer project
and took the losses.
All that does not tell us much about how supercomputers are built but it gives a picture that not only sciense dictates what is build or successful
Surprisingly enough supers are often built from existing CPU's but there ends all likeliness with existing hardware.
| Nizam Ali asked us: Why are thousands of processors used in supercomputers, why is there not one big processor used? (April 2003) | |
|
So the technology to make one
is not in place yet. What is needed is the implementation
of new technology, something like bio neural processors, quantum based
CPU's, based or not based on (sub)nano technology and, also an upcoming
field, CPU's based on light. |
|
Terms like super scalar, vector oriented computing, parallel computing are
just some of the terms used in this arena.
Since 1995 supers are build up from a GRID.
Meaning an array or cluster of cpu's (even ordinary PC's) connected by a special
version of e.g. Linux. Thus acting like one big machine. Nice to know is that
the costs of this type of supers are dramatically lower compared to the millions
of dollars costing "conventional" types. In 2004
But a fact is that supers are the fastest machines in their time. Yes have a smile looking at the Eniac. But back in 1942 it was a miracle machine and the fastest around.
There are three primary limits to performance at the supercomputer level: (1)
Input/output speed between the data-storage medium and memory is also a problem, but no more so than in any other types of computers, and, since supercomputers all have amazingly high RAM capacities, this problem can be largely solved with the liberal application of large amounts of money.(1)
The speed of individual processors is increasing all the time, but at great costs in research and development. The reality is that we are beginning to reach the limits of silicon based processors. Seymour Cray showed that gallium arsenide technology could be made to work, but it is very difficult to work with and very few companies now are able to make usable processors based on GeAs as the chemical notation is. It was such a problem back in those years that Cray Computer was forced to acquire their own GeAs foundry so that they could do the work themselves. (1)
The solution the industry has been turning to, of course, is to add ever-larger numbers of processors to their systems, giving them their speed through parallel processing. This approach allows them to use relatively inexpensive third-party processors, or processors that were developed for other, higher-volume, applications such as personal- or workstation-level computing. Thus the development costs for the processor are spread out over a far larger number of processors than the supercomputing industry could account for on its own. (1)
However, parallelism brings problems of high overhead and the difficulty of writing programs that can utilize multiple processors at once in an efficient manner. Both problems had existed before, as most supercomputers had from two to sixteen processors, but they were much easier to deal with on that level than on the level of complexity arising from the use of hundreds or even thousands of processors. If these machines were to be used the way mainframes had been used in the past, then relatively little work was needed, as a machine with hundreds of processors could handle hundreds of jobs at a time fairly efficiently. Distributed computing systems, however, are (or are becoming, depending on who you ask) more efficient solutions to the problem of many users with many small tasks. Supercomputers, on the other hand, were designed, built, and bought to work on extremely large jobs that could not be handled by another type of computing system. So ways had to be found to make many processors work together as efficiently as possible. Part of the job is handled by the manufacturer: extremely high-end I/O subsystems arranged in topologies that minimized the effective distances between processors while also minimizing the amount of intercommunication required for the processors to get their jobs done.(1) For example the ESS project has connected their clusters with glasfiber cables and uses special vector processors.
Operating systems are specifically designed for each type of supercomputer.
Sometimes a redesign of an existing OS will do the job if the super's CPU's
belong to the same family. But mostly, since the new computer really is something
new OS is needed.
In other cases one makes use of existing components, minor changes are needed
to make processors and IO peripherals talking to each other and the machine
is up and running. Building supers like that shortens the time to market sometimes
to one single year.
Operating systems of supers are not much different from other OS of other platforms.
They do their business on a different scale and internal communication to CPU's
and I/O is crucial. Sometimes OS's are splitting up in a " parallel way"
to take care for things independently from each other Most computers have a
internal clock that takes care for synchronizing the IO, some supers do not
even have a clock like that anymore.
The secret of whether or not a super is at its peak performance often lays
in the fine tuning. Just as with cars, a mal-tuned car uses a lot more gas and
runs slower than a well tuned car. Optimizing code for the Operating System
requires highly specialized programmers and scientists.
For example passing a string of bits from one memory module/location to another
and by optimizing this moving around of bits by just a millionth of a second
will make a big difference! Reaching that peak performance may take as much
as a few years. However a company may decide to leave part of this process to
the endusers, mostly scientists, because of economic reasons. Remember the 80/20
rule? With 20% of your effort you can realize 80% of your projects goal, but
with 80% extra time and money you may only improve 20%. So manufacturers tend
to negotiate a balance between effort and results. In the scientific world thing
are different: only the result counts.
Programming super computers is not a simple thing you take up as an afternoon programming job. It is very complicated to program a supercomputer. Sometimes an entirely new operating system is needed, or even a new programming language. But again as constructors do also programmers are reluctant to leave the proven technology behind.
There are several strategies that can be followed in programming supercomputers.
One of the most popular is called massive parallelism, There are advantages
but also disadvantages in parallel computing. It adds to the complexity of a
program and thus increases the number of bugs in the code.
Another one is distributed computing since 1998 even via the Internet (Seti@home, RCA key testing etc.)
Fact is that programming supers is the major overhead in projects. It can take another year after installing a super before the system becomes fully operational.
The most famous names are: Atanasoff, Eckert & Mauchly, Seymour Cray.
It is hard to tell which individuals were playing key roles (we will find out
though). Especially in this arena, constructing a super, is seldom an individual
but a team effort led by one or more companies.
In the mainframe area in the early 1960's the BUNCH were the major players in that field. Others entered the arena in supercomputing after CDC and Cray showed it was possible to create supers.
In 40 years (2004) there are but a few players left in the supercomputing arena:
Then there are super grids made by universities and the military, e.g. Virginia Tech with 1100 Apple G5 dual processors, and other mostly clusters of less powerfull machines with Linux special OS's for parallel processing.
Mostly one of the USA companies is holding the baton in supercomputing. But from time to time Japanese firms are taking over. Just like a tug of war game.
Conclusion
Supercomputers evolved from a single task oriented "CPU" (Eniac) to a multipurpose CPU - clustered - machine (Deep Thought - SGI). The picture shown below, taken from the top500 site(4), illustrates this nicely.
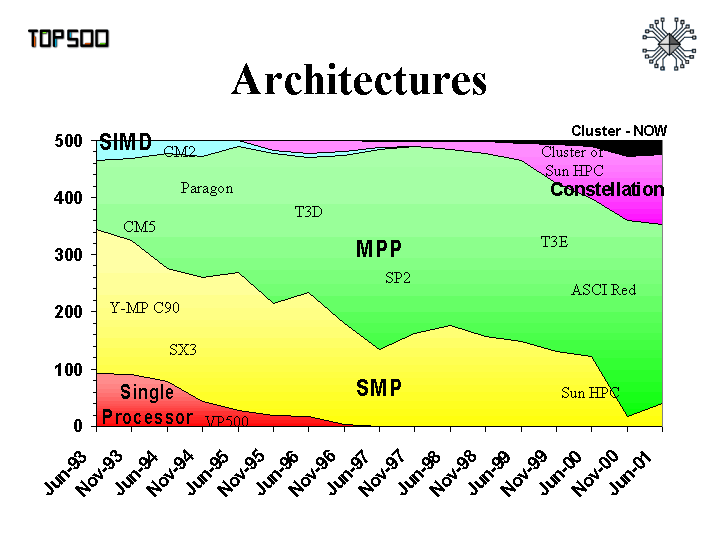 (4)
(4)
the graphic shows what type of architecture is involved with computers on the
top 500 ranking list (vertical bar)
The next generation of supercomputing is already announcing itself:
| Optical computing | Calculations with the (sub)speed of light via optical devices and connections. Transistors, the optical equivalent of them, are no longer switched by electrons but photons. |
| DNA computing |
Calculations by recombining DNA in a parallelish environment, |
| Quantum computing | Difficult to imagine but think of it that calculations are
done before you have thought it. Work is done in one blink of an eye since time is of no essence here. Massive computing by calculations done in different events of possibility. Don't say you weren't told ;=) |
All new technologies have one thing in common:
Things (calculations) are happening at the same time in different places.
Or in other words: you can build your roof at the same time as you build your wall and it all fits together! Like a prefab home that is put together on one spot within the blink of an eye. The prefabrication however is done in other workshops on different locations, all in the same time.
New materials are tested and new insights in programming will slowly get introduced. Demanding a new breed of programmers.
In all the fields, especially the hardware side, developments are taking place at top speed.
Off course it will take at least another decade before the new technologies will hit the workfloor. And again several decades later that same technology will be in place in our desktop machines, if we may still think that way about computer hardware.
Eventually economics will decide what we as users can afford to buy.
As always manufacturers will promise the new era of computing is just around the corner. Especially in this arena of computing: supercomputing.
Don't forget the time span it took (10-15 years) to get a new "high-tech"
product to the market gets shorter, (5-10 years) ironically because of more
supercomputing power becomes available.
Computers are constructing and testing new computers, which in their turn are
faster again and so on.
This concludes the introduction in supercomputing, If you have any questions, additions, better wording or any other comment please feel free to e-mail us.
![]()
| Last Updated on July 16, 2004 | For suggestions please mail the editors |
Footnotes & References
| 1 | Dan Calle - ei.cs.vt.edu/~history/supercom.calle.html |
| 2 | Apple.com |
| 3 | www.epm.oml.gov/ssi-expo/histext.html |
| 4 | www.top500.org |
| 5 | http://histoire.info.online.fr/vax.html |
| 6 | NEC's strategy in supercomputing (see hpc slide) |
| 7 | Excerpted from: The Architecture of Supercomputers: Titan, a Case Study, Siewiorek & Koopman, Academic Press, 1991, ISBN: 0-12-643060-8 |



 VAX
11-780
VAX
11-780